Százszor gyorsabb Big Data lekérdezéseket ígér a Hortonworks
2013. február 25.
 Üzleti intelligencia · BigData · Hadoop
Üzleti intelligencia · BigData · Hadoop
A Hortonworks új kezdeményezése a Hadoop adattárházas teljesítményének drámai javítását célozza.
A legnépszerűbb Big Data keretrendszernek számító Hadoop egyik komoly problémája, hogy az SQL-szerű interaktív lekérdezési lehetőséget biztosító Hive modul meglehetősen lassú.
A Hortonworks által most bejelentett Stringer célja a Hive teljesítményének nagymértékű, akár százszoros javítása, amit több lépéssel kívánnak elérni.
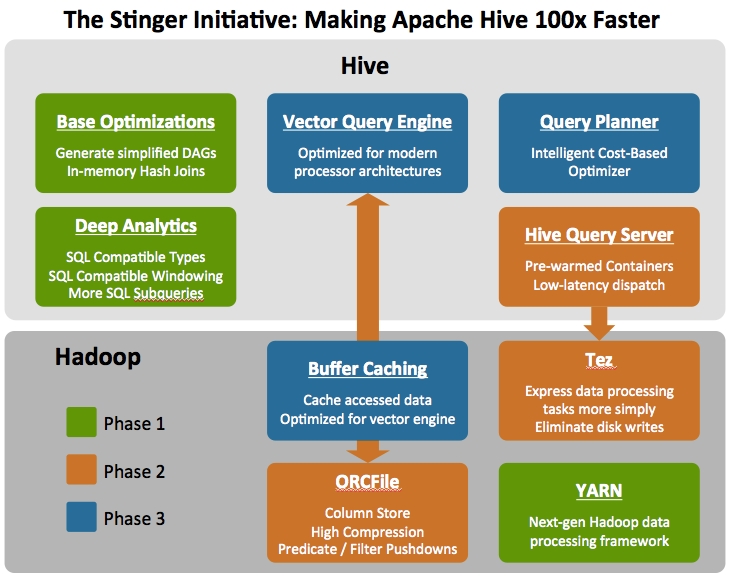 A Stringer komponensei A Stringer komponensei
Egyrészt a Hive által használt HQL lekérdezőnyelvet még közelebb hozzák az SQL-hez. Megjelenik például az Over() analitikus kiterjesztés támogatása és a WHERE klauzulákban allekérdezések is használhatóak lesznek. Továbbfejlesztik a lekérdezések végrehajtását tervező Hive optimizálót is.
Érdekes fejlemény, hogy megjelenik ORCFile néven egy új, oszlopalapú adattárolást biztosító formátum, amely az eddig használt megoldásoknál sokkal jobb teljesítményt ígér. Végül Tez néven egy új runtime keretrendszer is készül, amely sokkal kisebb latenciával lesz képes futtatni a Hive lekérdezéseket.
A Hortonworks márciusra ígéri az új komponensek előzetes verzióját.
A Hadoop adattárházas teljesítményének javítása más gyártóknál is fontos szempont.A nagy vetélytárs Cloudera tavaly ősszel mutatta be saját, Impala nevű megoldását.
További információ
 hortonworks.com hortonworks.com
Kapcsolódó anyagaink
|

